Baselines
Demonstration Against Human Experts
Random Action Agent
Our RandomActionAgent is a basic demonstration of an agent interacting with the environment which we explain in the Getting Started section of the docs. This agent simply takes random actions in the environment with an action space that is restricted to only take non-negative acceleration values.
Usage
As mentioned previously, you need to have the docker image with the simulator to use the environment. Simply add the -b flag and argument random as a command line argument to ./run.bash to use this agent.
$ chmod +x run.bash # make our script executable
$ ./run.bash -b random
Soft Actor-Critic
We also provide a more detailed demonstration of how to use the environment with our Soft Actor-Critic agent using OpenAI’s Spinning Up Pytorch implementation with minor adjustments. Specifically these adjustments include wrapping methods which returned observations from the environment to first encode the raw images into a latent representation, waiting until the end of the episode to make gradient updates, and removing unused functionality.
Training Performance
For both tracks, we provide our agent’s model after 1000 episodes which was slightly less than 1 million environment steps for the Las Vegas Track and slightly more for the Thruxton track.
Las Vegas Track
Our agent is able to consistently, but not always, complete laps in under 2 minutes each.



Thruxton
The agent demonstrates control but fails to ever complete a lap due to the trap near the end of the course which requires multiple sharp turns.

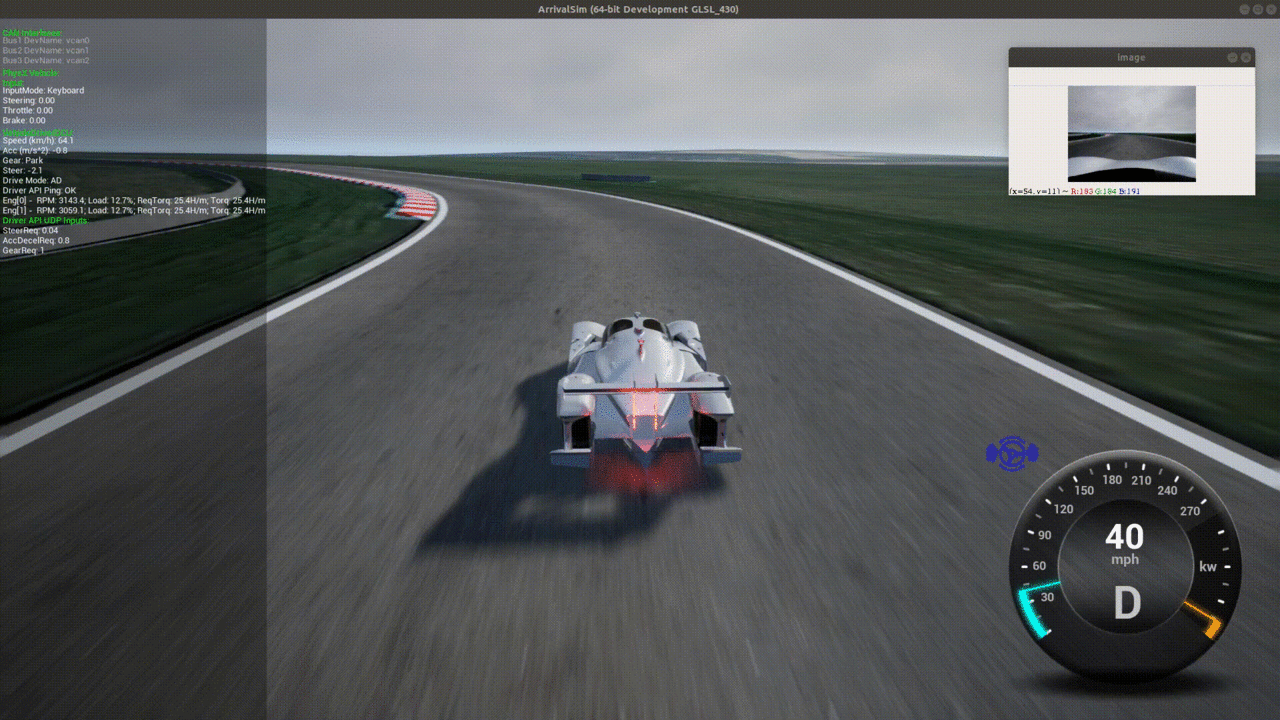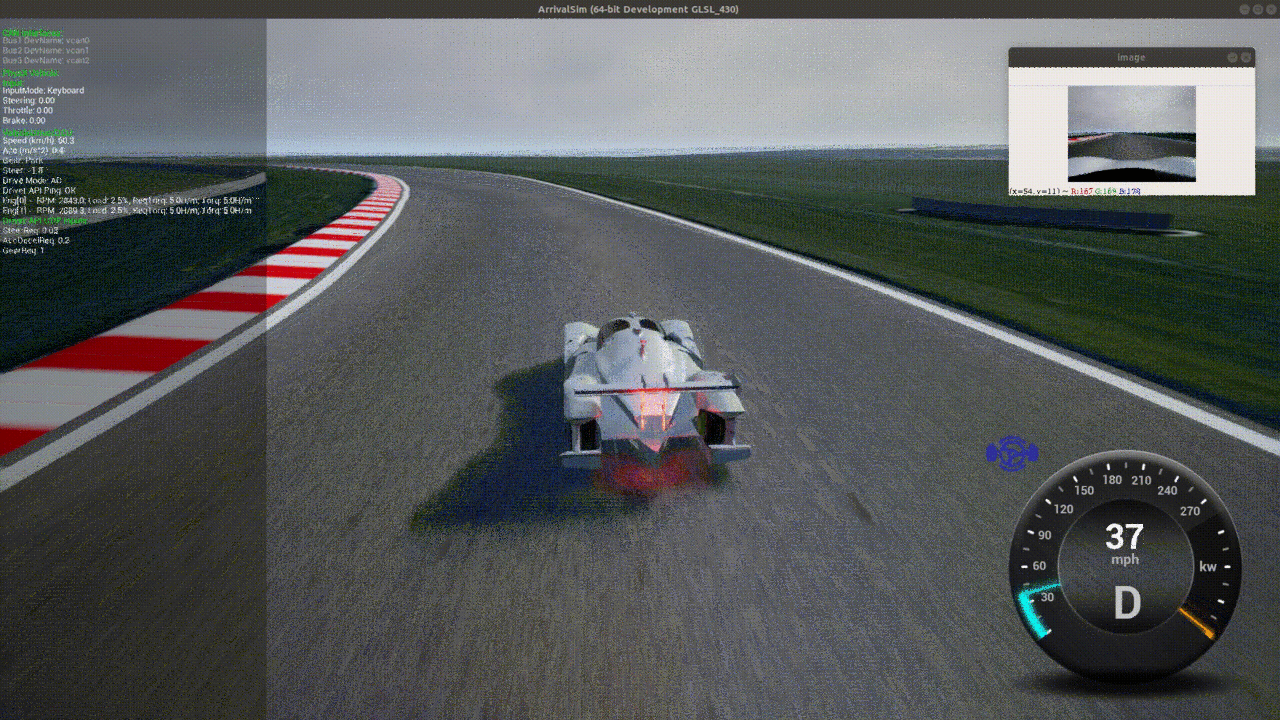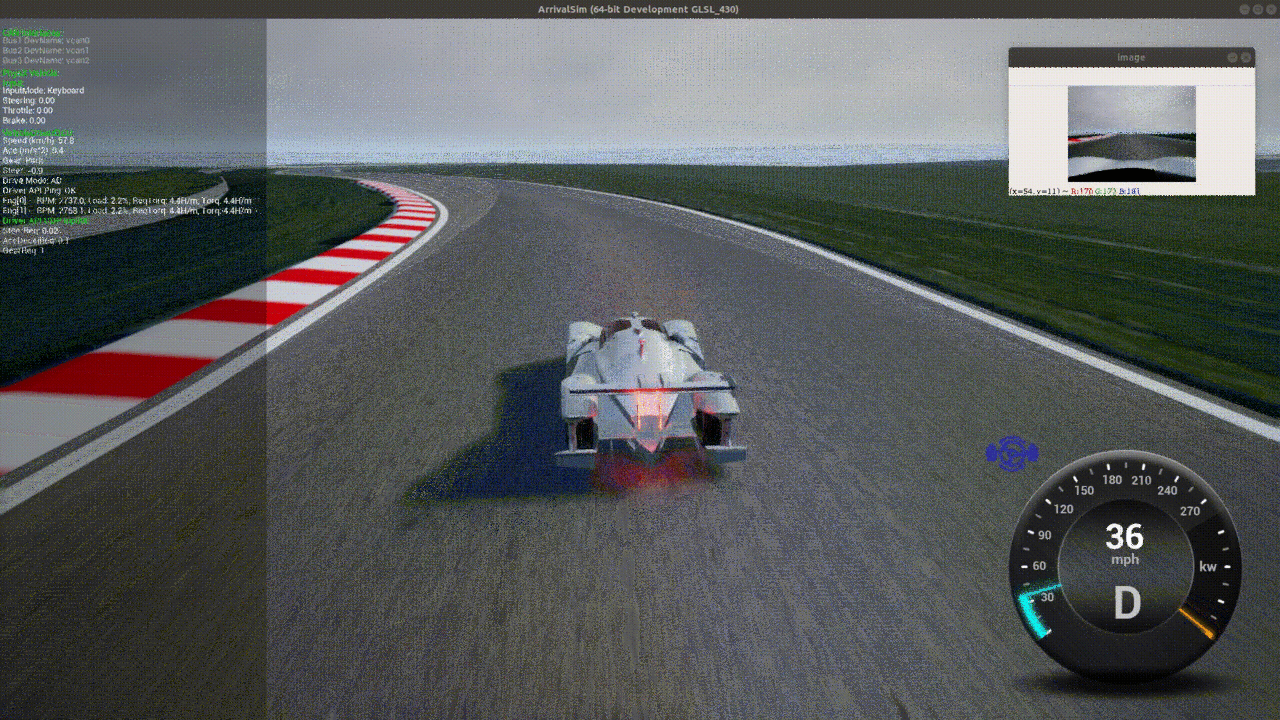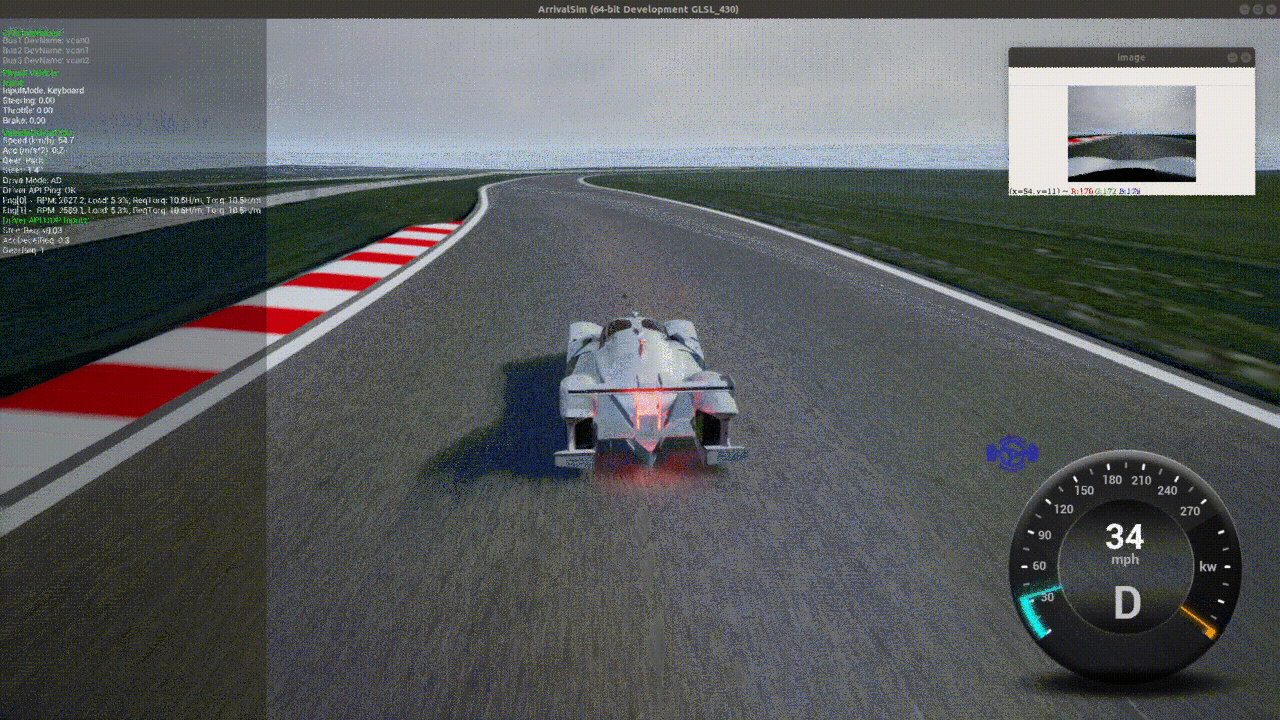
Evaluation Performance
The SAC agent struggles when transferring its learned experience from the Thruxton track to the Las Vegas evaluation track even after 60 minutes of exploration as it learns to simply stop in the middle of the track to avoid the penalty of going out-of-bounds.
Usage
To run the trained model, simply provide -b flag and argument sac to run.bash. Both the encoder and checkpoint models were trained separately for each track, so if you would like to switch to the Thruxton track, be sure to change the encoder and checkpoint paths in configs/params_sac.yaml in addition to the track name.
$ chmod +x run.bash # make our script executable
$ ./run.bash -b sac
Vision-Only Perception & Control
This agent learns non-trivial control of the race car exlusively from visual features. First, we pretrained a variational autoencoder on the provided sample image datasets to allow our agent to learn from a low-dimensional representation of the images. Our VAE is a slight modification of Shubham Chandel’s implementation.
Restriction of the Action Space
For this agent, we restricted the scaled action space to [-0.1, 4.0] for acceleration and [-0.3, 0.3] for steering to allow for faster convergence.
Custom Reward Policy
Additionally, we modified the default reward policy for the environment to include bonus if the agent is near the center of the track for each step in the environment but only if it had made progress down the track. Doing so has numerous consequences including:
encouraging the agent to safely stay near the middle of the track
disincentivizing the agent from engaging in corner cutting
implicitly rewarding the agent to drive more slowly
As such, this reward allows for faster convergence in terms of number of episodes before completing its first lap in the environment. However, we noticed that the agent learns to zig-zag; we believe this may be an intentional effort to slow down and gather more near-center bonuses.
Model Predictive Control
We include a model predictive control (MPC), non-learning agent with the environment too. This reference implementation demonstrates a controller which attempts to minimize tracking error with respect to the centerline of the racetrack at a pre-specified reference speed.
Performance
The MPC agent does well, completing laps consistently, on the Thruxton track by following a conservative trajectory. On the LVMS track, however, it seems to occasionally falter on the highest curvature points of the track.
Usage
To run the trained model, simply provide the -b flag and argument mpc to run.bash. Do note, however, that the MPC requires torch<=1.4 unlike the SAC baseline.
$ chmod +x run.bash # make our script executable
$ ./run.bash -b mpc